13 Wed
TIL
[AI 스쿨 1기] 6주차 DAY 3
선형 분류(Linear Classification)
클래스의 사후확률 (using 베이즈 정리) 또는
직접 모델링
직접 모델링
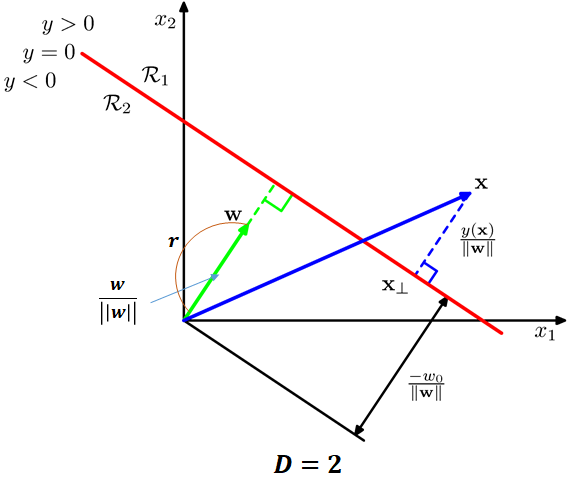
판별함수 (Discriminant model)
: wight vector
: bias
이면 클래스 1로 판별, <0이면 클래스 2로 판별
결정 경계면 위
→ 즉,
는 결정경계면에 수직
이면, 결정 경계면은 원점으로부터 w가 향하는 방향으로 멀어져있음.
이면, 결정 경계면은 원점으로부터 w가 반대 방향으로 멀어져있음.
즉,
이면, x는 결정 경계면 기준으로 w가 향하는 방향에 있음
이면, x는 결정 경계면 기준으로 -w가 향하는 방향에 있음.
의 절댓값이 클수록 더 멀리 떨어져있음.
(수식 단순화) 가짜입력 dummy input
이용
클래스
에 대해 표현하면 다음과 같음.
일 때,
를 만족하면, x를 클래스
로 판별

분류를 위한 최소제곱법 (Least squares for classification)
행렬
에 대해 나타내면,
학습 데이터
,
, n번째항이
인 행렬 T, n번째 행이
인 행렬
이 주어졌을 때, 제곱합 에러함수는 다음과 같음.
에 대해 미분하고 식 전개하면,
(
: pseudo-inverse 행렬)
퍼셉트론 알고리즘 (The perceptron algorithm)
여기서
이며, f는 활성함수(activation function)로 계단형 함수임
: 잘못 분류된 데이터들의 집합
확률적 생성 모델 (Probabilistic Generative Models)
모델링 한 다음 → 클래스의 사후확률
을 구함❗ (using 베이즈 정리)
(a에 관한 logistic sigmoid function)
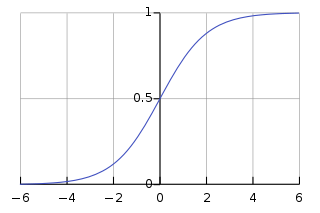
대칭 :
역(inverse) :
(a에 관한 softmax function)

가 가우시안 분포를 따르고, 모든 클래스에 대해 공분산이 동일하다고 가정하자.
실제 데이터
에 대해
이면 클래스 1로 분류하고,
은 클래스 2로 분류.
라 할때, 구하고자하는 파라미터는
❗
데이터가 이산일 때 (Discrete features)
각 특성
이 0 또는 1, 하나의 값만 가질 수 있는 경우
이때,
이며, 위 식을 k-class의
에 대입하면 다음과 같음.
함수에 대해 선형인 것을 확인할 수 있음.
[Statistics 110]
Present Part [3 / 34]
3강- Birthday Problem과 확률의 특성 (Birthday Problem, Properties of Probability)
생일 문제 : 생일이 같은 두 명의 사람을 찾기
최소한 몇명의 사람이 있어야 50%의 확률을 만족할까?
모두의 생일이 같지 않을 확률
k에 대한 직관
확률 정리
몽모르트 문제 : 드 몽모르트가 만든 문제
Last updated