12 Tue
TIL
[AI 스쿨 1기] 6주차 DAY 2
선형회귀(Linear Models for Regression)
선형 기저 함수 모델
기저함수(basis function) :



최대우도와 최소제곱법(Maximum Likelihood and Least Squares)
: 결정론적 함수(deterministic)
: 노이즈 확률변수
입력 값 :
출력 값 :
로그우도함수 최대화시키는 w값 =
로 주어진 제곱합 에러함수 최소화시키는 값❗
w의 최적값 :
(normal equations)
의 Moore-Penrose pseudo-inverse :
design matrix의 모든 열이 선형 독립이면,
존재❗ (항상성립하진 않지만 많은 경우에 성립하며, 성립하지 않은 경우에 대해 성립하도록 데이터 조절 가능)
구한 에러함수를 편향 파라미터(bias parameter)
로 표현하면
이때
는
의 차이를 보정해주는 역할❗

온라인 학습 (Sequential Learning)
에러함수가
라 할때,
으로 학습 진행
으로 표현
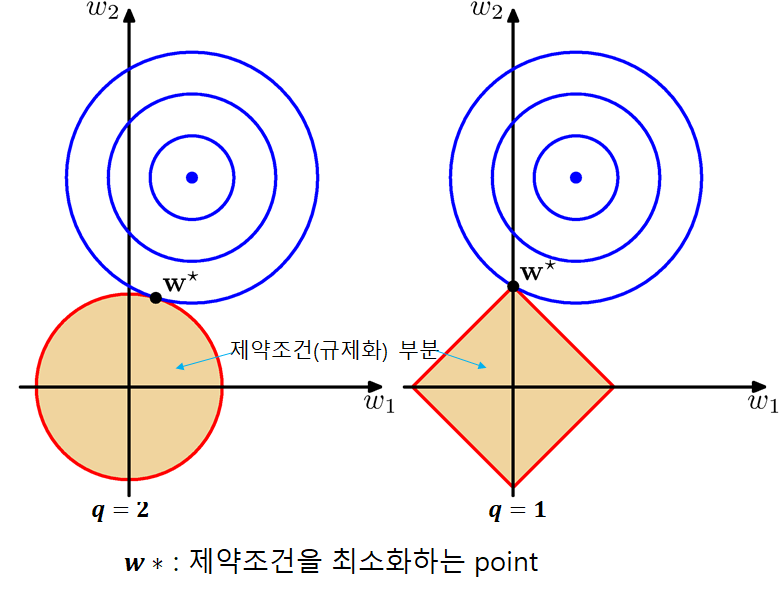
규제화된 최소제곱법(Regularized Least Squares)
w에 대해 미분하고, 정리하면 w의 최적값 ->
를 만족하면서
를 최소화시키는 해 찾기 !

편향-분산 분해(Bias-Variance Decomposition)
에 대해 변형하면
정리하면,
베이지안 선형회귀(Bayesian Linear Regression)
사전 확률의 공분산
이라고 가정하면,
,
수렴
mN에 대입하면,
(normal equations)
[Statistics 110]
Present Part [2 / 34]
2강- 해석을 통한 문제풀이 및 확률의 공리 (Story Proofs, Axioms of Probability)
10명을 4명과 6명으로 나누어 두 팀을 만드는 경우의 수
10명을 5명과 5명으로 나누어 두 팀을 만드는 경우의 수
복원 가능, 순서 미고려
n개의 구분 가능한 박스 안에 k개의 구분 불가능한 입자를 넣는 방법
이야기 증명(Story Proof)
확률
Last updated