11 Mon
TIL
[AI 스쿨 1기] 6주차 DAY 1
가우시안 분포(Gaussian Distribution)
: D차원의 평균 벡터
: DxD크기를 가지는 공분산 행렬
따라서,
대칭행렬의 성질에 따라서
쉽게 구할 수 있음.
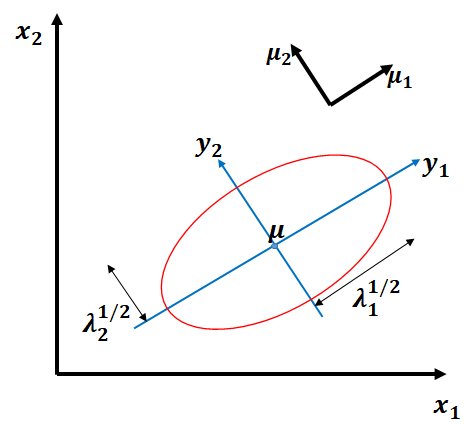
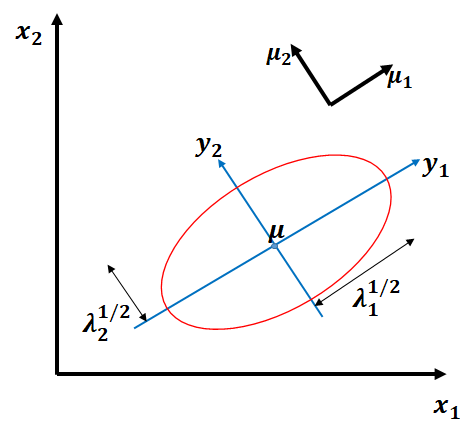
y를 벡터들
에 의해 정희된 새로운 좌표체계 내의 점으로 해석 → 이를 기저변환(change of basis) 라 함.
: standard basis에서의 좌표
: basis
에서의 좌표
를 구해야 함❗
행렬식
는 고유값의 곱으로 나타낼 수 있음
(
부분이 남기때문에)
는 DxD 행렬이므로
를
로 치환하면,
는
개의 행렬 합이며 그 중
에 관해 영행렬이 됨.
( [ ]안의 식이 odd function이므로)
: 상수부분
나머지
부분에 관해서는 odd function의 성질로 사라지며, 마지막
은 별개의 부분으로 적분 앞으로 나옴.
따라서 정리하면,
임.
위에서 게산한 결과를 이용하면,
❗

조건부 가우시안 분포(Conditional Gaussian Distribution)
D차원의 확률변수 벡터 x가 가우시안 분포
를 따른다고 하자. x를 두 그룹의 확률변수들로 나눴을때, 한 그룹이 주어졌을때 나머지 그룹의 조건부 확률도 가우시안 분포를 따르며, 각 그룹의 주변확률변수 또한 가우시안 분포를 따름.
: M개의 원소를 가짐.
평균벡터 :
공분산 행렬 :
의 형태를 가진다고 하자.
공분산의 역행렬 :
( 정확도 행렬(precision matrix)를 사용하는 것이 수식을 간편하게 함)
라 하며, 이때 이 함수의 적분이 1이고, α는
α는
의 주변확률.
이므로,
❗
즉, 함수
를 찾는 것이 목표
❗
α에 해당하는 부분 :
따라서 공분산 ->
이를 통해 일차항을 정리해서 계수를 통해 평균벡터를 구하면,
주변 가우시안 분포(Marginal Gaussian Distributions)
이때, β는
파티션을 위한 이차형식을 다시 살펴보면, 전체 16개 항 중
정리하면,
를 완전제곱식 형태로 만들기
치환해서
를 빼주고 더해주면 다음과 같이 변형됨.
이는 공분산
에만 종속되며,
의 지수부에 집중하면 됨❗
따라서,
에 관해 정리하면,
by Schur complement
가우시안 분포를 위한 베이즈 정리(Bayes' Theorem for Gaussian Variables)
의 평균은 x의 선형함수
구할 값 :
를 위한 결합확률분포 (이를 통해 공분산, 평균벡터 계산)
조건부 가우시안 분포 결과 를 적용하여 조건부 확률
의 평균과 공분산은 다음과 같음.
가우시안 분포의 최대우도(Maximum Likelihood for the Gaussian)
가우시안 분포에 의해 데이터
가 주어졌을 때 우도를 최대화하는 파라미터 값(평균, 공분산) 찾기❗
우도를 최대화하는 평균벡터
치환
우도를 최대화하는 공분산 행렬
이해하기
가우시안 분포를 위한 베이지안 추론(Bayesian Inference for the Gaussian)
MLE방법은 파라미터들
의 하나의 값만 구했다면, 파라미터의 확률분포 자체를 구할 수 있음❗
우도함수
와 사전확률
를 통해
구하기❗
Last updated